Self-Improvement via Synthetic Data Augmentation
4/10/2025
Suhas Kotha, Ludwig Schmidt, and Tatsunori Hashimoto
Introduction
Motivation
Though we have found great success from training language models on increasing amounts of data, the party ends once we run out of data, as early as 2 years from now (Villalobos et al, 2024). This is especially concerning for tasks under-represented on the internet such as rarely occurring facts (i.e. “what dataset does this paper use”). One concern is that once we've crawled every link and trained on every webpage, pretraining will hit a data “wall” and the current scaling paradigm of increasing compute will stop seeing significant performance improvements.
How can we deal with this lack of human data? Since we have already trained such capable language models, can they generate more useful training data? If the “synthetic data” generated from these models is useful, we can continue improving performance past the data-constrained barrier. Recent research has found many ways to generate helpful training data. These algorithms generally fall under a couple of common approaches to ensure the synthetic data is useful training data.
- Distillation Data: To train a student model, we can generate helpful data from a trusted teacher model. For example, TinyStories (Eldan et al, 2023) aims to train small models that are good at generating short stories. They collect this data by prompting an existing model (ChatGPT) to generate high-quality representative stories. This generated dataset is helpful for the smaller model, enabling performance that would have otherwise required much more training data.
- Consistency Data: Certain domains have a source of high-quality supervision external to the training data. For example, the programming language Lean can automatically check whether a proof attempt for a math problem is correct. In this case, model generations can be filtered to be consistent with the external supervision. In AlphaProof (Deepmind, 2024), Lean is used to filter model generations for new unsolved problems. The remaining correct solutions can be used as training data to improve model performance.
- Data Augmentation: One approach we are particularly excited about is data augmentation, or generating new training documents by perturbing/reformatting existing documents. This is generally easier than generating new documents from scratch since the new document can be grounded in the contents of the original documents. In the past, the vision community has found data augmentation (i.e. image blurring) to generate helpful training data for the data-limited regime of ImageNet. Inspired by this, several recent methods have found success using existing language models to augment a training corpus. For example Maini et al, 2024 uses a language model to rephrase training data for pretraining. Yang et al, 2024 uses language models to explicitly describe the relationships between entities in a document to generate more data grounded in a small continual pretraining corpus.
Self-Improvement
The success of synthetic data opens an exciting promise: can existing language models improve themselves? In its purest form, models would be able to generate training data for themselves that enables continual self-improvement without access to (1) an already more capable model or (2) a domain-specific verification signal. Because of this, we study the possibility of data augmentation to enable self-improvement.
To study whether models can improve themselves, we start with an existing pretrained model. In a continual pretraining setup, we find that data augmentation via rephrasing can improve model performance on a small corpus of data with constant accuracy gains for every constant multiple of rephrases generated/trained on. However, this does not work well for all of our domains. For example, even with a dataset thats sufficient to increase model performance by 12.6% via RAG, data augmentation only results in a 3.0% improvement. This raises a question of why different setups result in varying data augmentation success. More importantly, it raises the need for synthetic data strategies that more generally improve model performance.
Are there limits to how much data augmentation can improve performance? To better understand this, we try improving the data generator by either increasing model parameters or increasing its domain-specific knowledge. In either case, we do not find significant improvements in the quality of the generated data, raising concerns about a limit to how much data augmentation can improve performance. We believe that bypassing this limitation will likely require new synthetic data strategies that better leverage improved model capabilities.
Our experiments on synthetic data raise two important questions for future studies.
- Motivated by our domain discrepancy in rephrasing, is there a data augmentation strategy that universally improves performance along axes? Alternatively, will synthetic data have to be hand-crafted to target specific domains/capabilities?
- For our specific domains and rephrasing strategy, we find limited success in scaling the rephraser. Do other strategies better leverage a more capable generator (which is more likely to be useful as models get more capable)?
Act 1: Data augmentation (sometimes) works
Prior work has found that language models can produce helpful synthetic data via data augmentation. One of the simplest augmentations that language models can perform to generate more documents is rephrasing, studied by the excellent work Rephrasing the Web Maini et al, 2024. To generate pretraining data for a 350M or 1.3B parameter language model, they use an existing generator model (i.e. Mistral-7B) to rephrase pretraining documents in 4 different styles. They find that pretraining on this augmented corpus (in combination with the original data) leads to higher downstream performance compared to training on the original pretraining corpus (Figure 1).

One concern with this work is that the generator model is more capable than the student model. In this case, the benefit may come from distilling a teacher model's capabilities rather than pure data augmentation. We can control this confounder by setting our student model to be the same as the teacher model. This controls for the capability gap, leading to cleaner attribution for any future performance improvement. We study this continual pretraining across three different domains.
- Inspired by Yang et al, 2024, we consider Quality (Pang et al, 2021), a corpus of 266 articles constituting 1.5M tokens. The benchmark comes with an associated 4609 MCQ questions that can be used to test whether the model knows the contents of the articles. The original paper has tried rephrasing as a baseline, finding it successful when using GPT-4 as the generator.
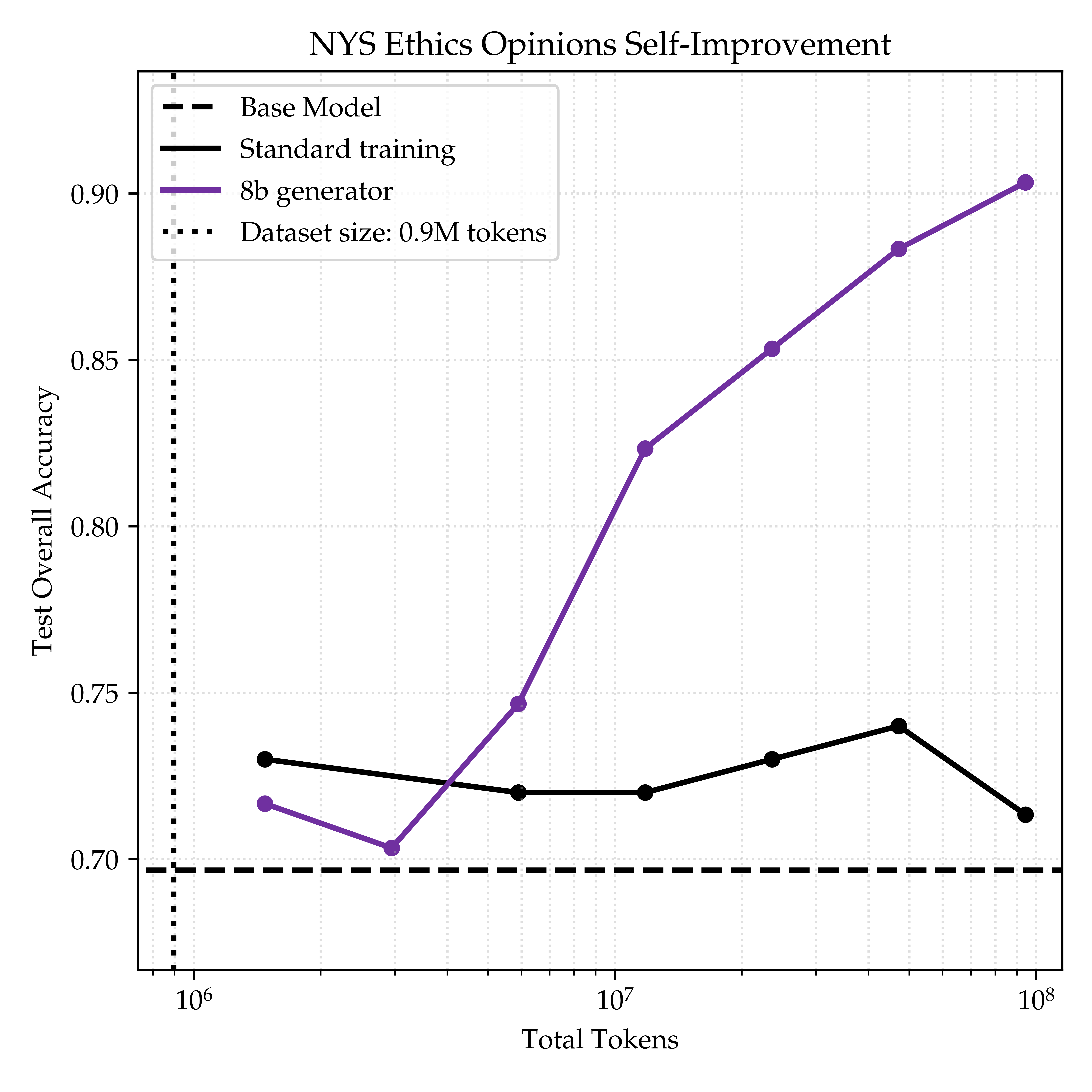
- We consider the New York State Ethics Opinions dataset from LegalBench (NYS for short) (Guha et al, 2023). This benchmark consists of 300 true or false questions based on statements issued by judges over multiple years. All the questions are grounded in publicly posted ethical opinions, constituting a training corpus of 0.9M tokens.
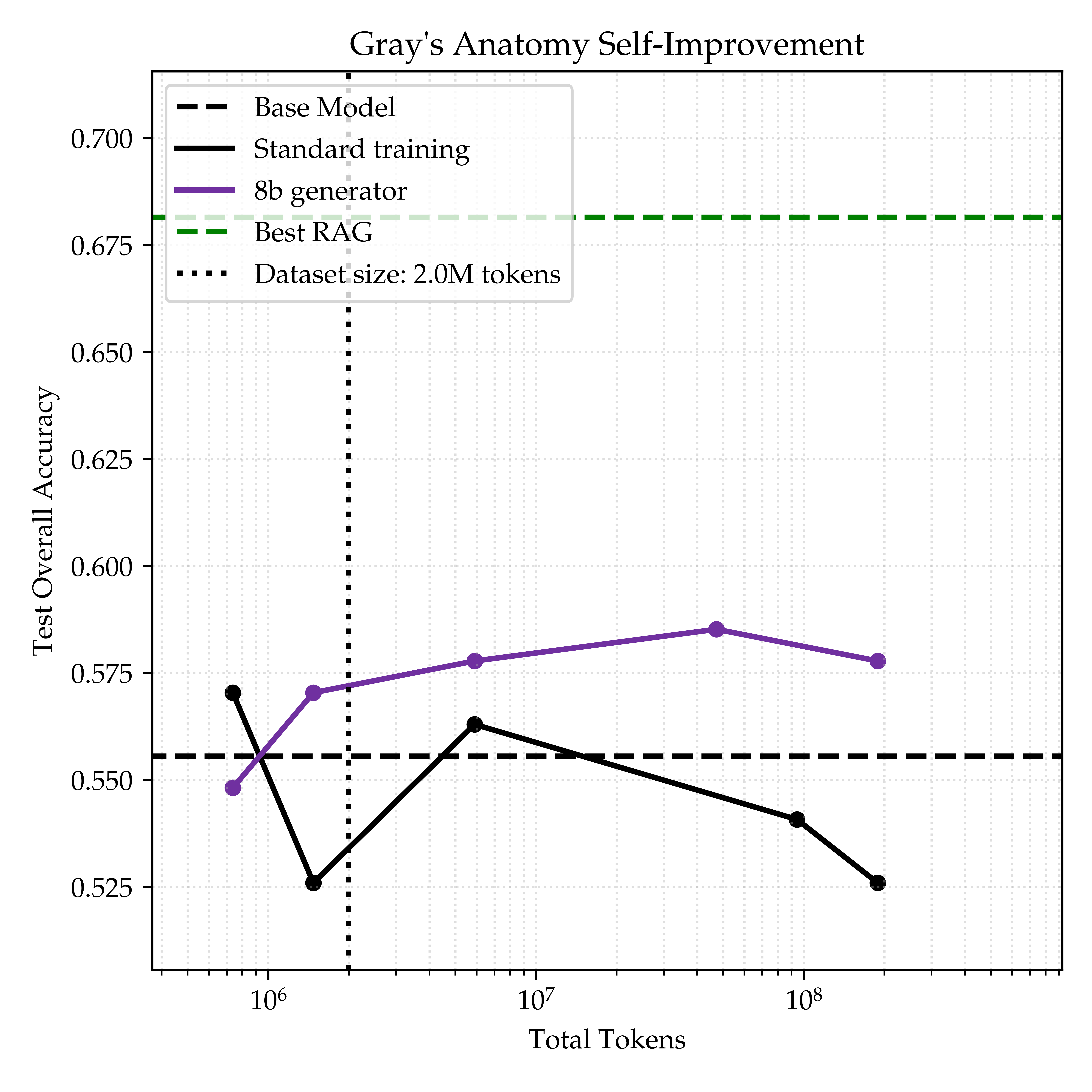
- We consider testing domain-specific knowledge via corresponding MMLU splits (Hendrycks et al, 2020). For a given MMLU split, our raw data consists of textbook(s) related to the topic. One motivating example is measuring performance on MMLU anatomy (135 questions) given access to Gray's Anatomy (2M tokens).
We use Llama 3.1 8B Instruct for our model. We choose the instruct version so the model can readily perform the rephrasing task. For this model, we compare training on the original data vs training on the rephrased data in Figure 2. We first find that training on the original data results in little performance improvement. For example, it helps at most 3.5% on Quality when training on up to 840M tokens. On the other hand, training on the rephrased data results in a 16.6% performance improvement in Quality for the same number of tokens. The performance continues to improve even after seeing hundreds of rephrases of the original documents. This improvement is substantial compared to the RAG system for Quality in Yang et al, 2024 which gets a 21.86% improvement by retrieving Quality documents to put in context.
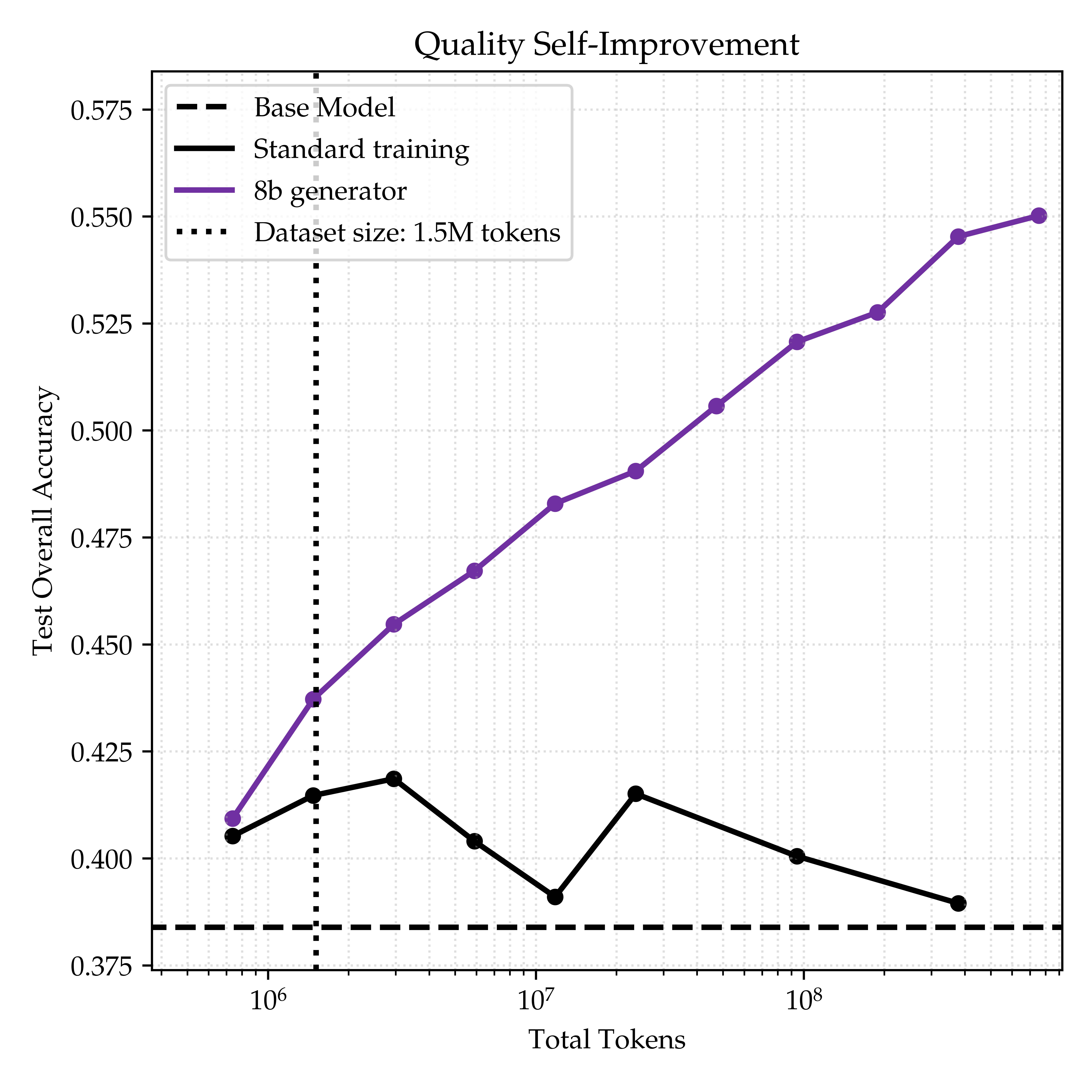
On the contrary, continual pretraining does not have the same success for the MMLU domains. MMLU anatomy paired with Gray's anatomy is a particularly striking example, shown in Figure 3. Training on the original textbooks gives at most 1.5% improvement. Meanwhile, training on the rephrased textbooks gives at most 3.0% improvement. A naive application of RAG with a BM-25 retriever dwarfs either of these methods with a 12.6% improvement (more details in Appendix A.3).
Open Problem
Why does rephrasing work so well for Quality and NYS but not MMLU? Is this limited to rephrasing, or is there a real bottleneck to using data augmentation for certain domains? One possible hypothesis for the difference is that the questions for Quality and NYS are “tightly coupled” with the corpus, collected specifically to test knowledge on those documents. On the other hand, the MMLU questions were most likely not directly taken from the textbooks we chose to train on, indicating they are more “weakly coupled” with the corpus. This gap between the data and question collection might cause additional complications for synthetic data which future work could aim to resolve.
Act 2: Improving the generator does not significantly help
The previous section indicates that synthetic data offers clear benefits for downstream model performance for certain domains. An impressive aspect is that the generator could be the same as the student model, leading to self-improvement. This opens a home for recursive self-improvement: if our current generators can improve students, and these students could in turn be used as generators, then we could repeat this process for increased performance improvement. However, this crucially depends on whether improving the generator results in better student model training. If improving the generator doesn't help, then this recursive self-improvement would not outperform the self-improvement we previously identified.
This section systematically measures how changing the generator affects performance improvement. We experiment with modifying the generator along two natural axes: increasing parameter count within the same model family, and training the generator on the corpus to increase domain-specific knowledge.
Scaling Parameter Count
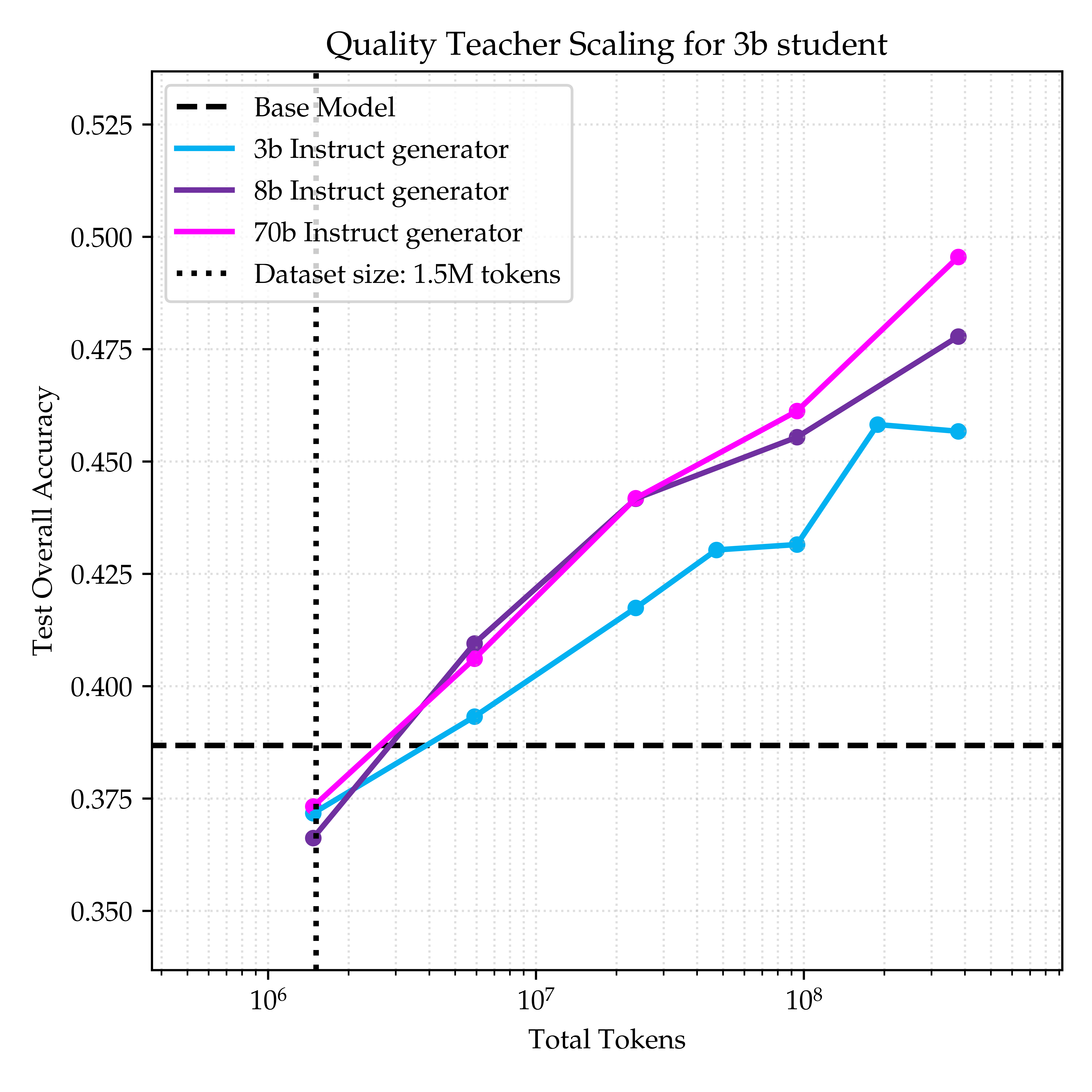
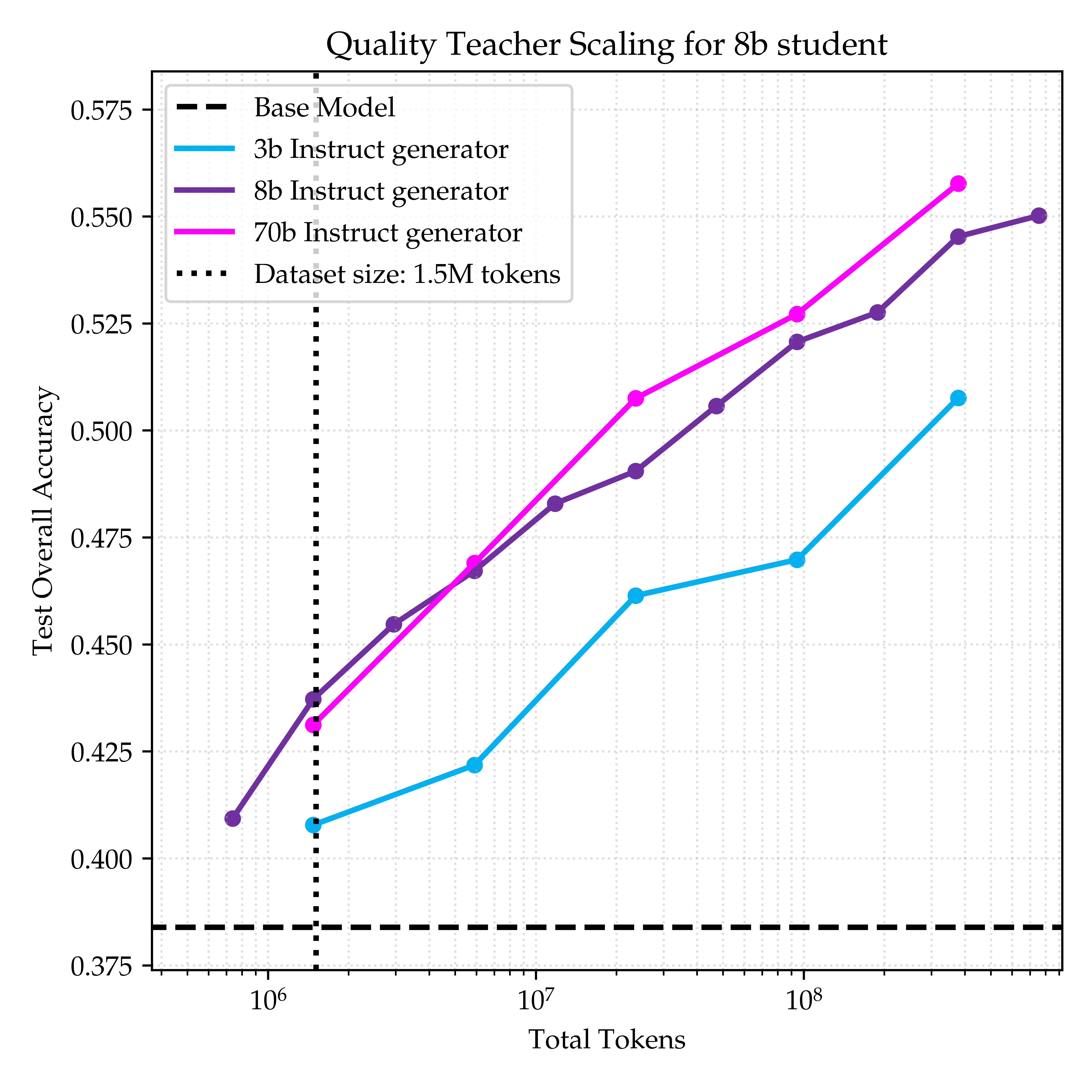
The simplest way to improve the generator is to try larger models. Intuitively, this captures increasing the generator's capabilities, hopefully resulting in higher-quality rephrases. In Figure <>, we show the results of training a Llama 3B or 8B Instruct student on data generated from teachers of Llama 3B, 8B, or 70B Instruct for up to 420M tokens. For the 8B student, taking the generator from 3B to 8B results increases performance by 3.8% at the largest scale. Increasing the generator from 8B to 70B doesn't have the same impact, only increasing performance by 1.2%. The same results qualitatively hold for a 3B student (barring a small deviation at the maximum token count tested which may or may not be significant). For this experimental setup, the benefits of using a larger generator plateau relatively quickly, and it might be a better investment to use a smaller generator for more synthetic tokens. This agrees with previous findings that weaker generators can be used for synthetic data augmentation (Allen-Zhu et al, 2023) and consistency data (Bansal et al, 2024).
Scaling Domain-specific Knowledge
To simulate a generator with more domain-specific knowledge, we consider using generators that have been trained to model the corpus. Specifically, we use the following pipeline
- Use Llama 8B Instruct to generate synthetic data
- Train Llama 8B Instruct on this synthetic data as earlier and save this model
- Use this new model to generate new synthetic data
- Train Llama 8B instruct on this new synthetic data
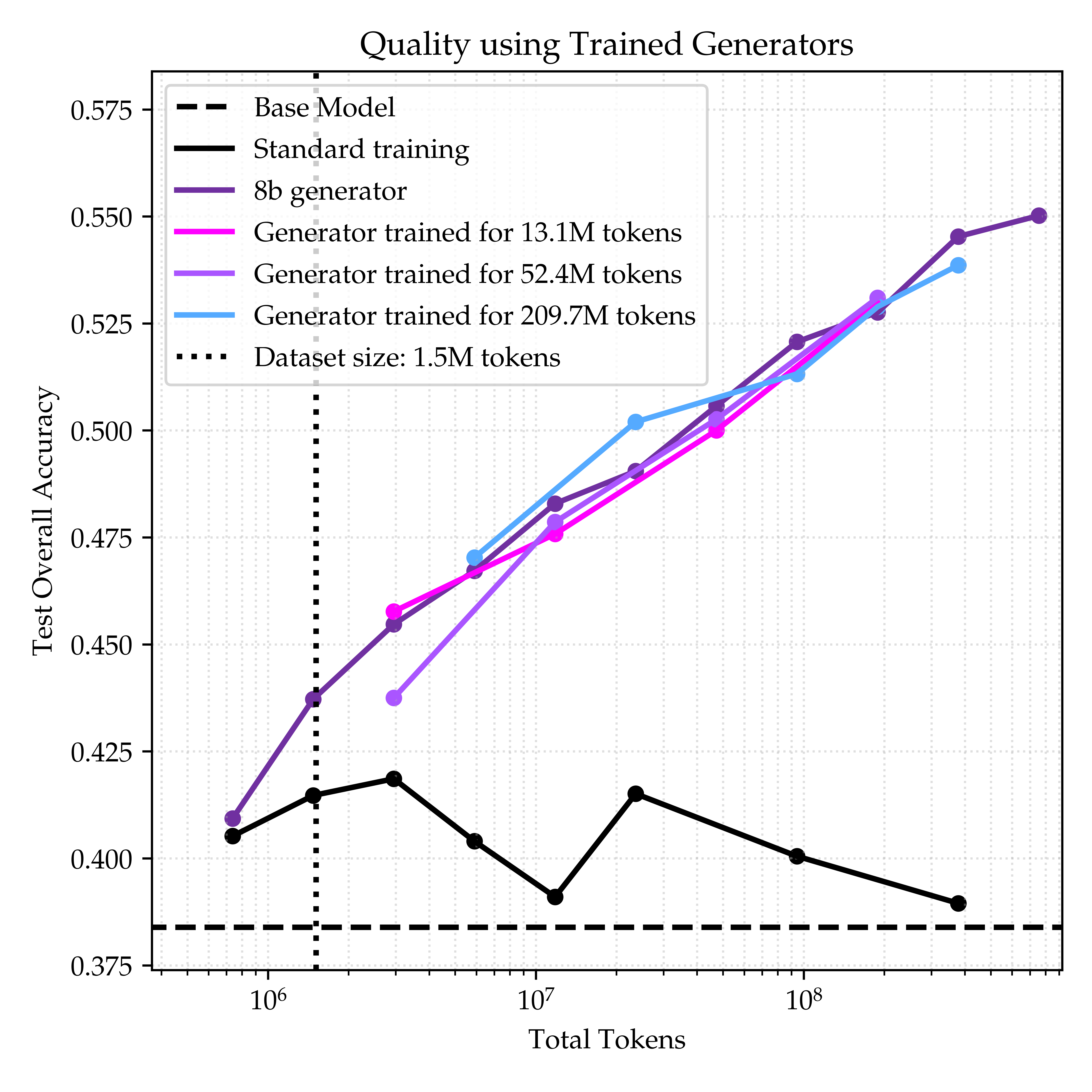
One hope is that models trained on this corpus may better understand the domain's documents, enabling higher-quality rephrases. In Figure 5, we compare how using synthetic data from trained generators compared to using the original model. We find that both methods have similar scaling trends, indicating that the trained generators do not produce more helpful synthetic data.

Open Problem
In our setting data augmentation does not strongly benefit from using larger or domain-trained generators. This makes recursive self-improvement via data augmentation seem less feasible. Are there any data augmentation schemes that admit recursive self-improvement? There are a few possibilities here
- Augmentation strategy: Rephrasing may be a sufficiently easy augmentation that does not have a high capability ceiling. Therefore, trying to improve the quality of rephrases is bounded, whereas more complicated augmentations admit more self-improvement.
- Data domains: This form of self-improvement only occurs for specific domains that are not Quality, NYS, or MMLU. One possibility is this applies to “multi-hop” datasets where questions rely on knowledge across multiple documents, compared to our current datasets where many questions can be answered by one document.
- Different scaling axes: There are other ways of improving the generated synthetic data such as introducing scores for the quality of each document. It's possible that one of these modifications can result in more performance improvement.
It is also possible that recursive self-improvement is not best done with data augmentation. In any case, it is valuable to understand how synthetic data generation interacts with improving generators.
Conclusion
Synthetic data is helpful for data augmentation for some domains, even for hundreds of augmentations. However, simple data augmentation strategies such as rephrasing do not benefit from improving the generator. We hope these findings inspire future synthetic data algorithms that (1) work more universally and (2) scale better with generator improvements. Thank you for reading, and feel free to reach out with any questions or thoughts! I have a lot of thoughts on this topic and would love to chat more or share additional experiments I've run.
Acknowledgements
This was my first rotation project at Stanford where I had a great time being advised by Tatsunori Hashimoto and Ludwig Schmidt. I want to specially thank Zitong Yang and Konwoo Kim for many helpful discussions throughout this project, as well as labmates in Tatsu's and Ludwig's labs.
Appendix
A.1 Data Generation Details
For rephrasing, we use the original easy, medium, hard, and QA prompts. We use vLLM to generate the synthetic data. We always use decoding with temperature 0.7 since we found that temperature 1.0 led to less factual synthetic data under visual inspection. Since all documents fit within the model context for Quality and NYS, we rephrased the entire document. For MMLU, since each textbook was too long to fit within context, we split each textbook into approximately 4,000-character chunks while trying to keep textbook paragraphs intact. Then, we ask the generator model to rephrase each chunk separately.
A.2 Training Details
We use a cosine learning rate schedule with a 5% warmup with a maximum learning rate of 5e-6. Each point in a plot corresponds to an independent training run with a separate learning rate schedule to enable cleaner scaling. We found 5e-6 to be the best learning for the original and synthetic data. We replay OpenHermes instruction-tuning data for 10% of the tokens to prevent catastrophic forgetting. All training runs are done in parallel on 4 GPUs with batch size 4
A.3 RAG Details
We implement a RAG baseline to measure how much the knowledge in the training corpus can increase model performance. We use the following pipeline.
- Take the textbook chunks used for continual pretraining for MMLU
- Use a BM-25 retriever to find the 5 nearest chunks for each question (for the same chunks used in training).
- Measure the model accuracy on the MMLU split using the top k nearest chunks in context for k in {0, 1, 2, 3, 4, 5}. For evaluation/formatting, we use RAG evaluation harness.
- Select the maximum accuracy of the six candidates as “Best RAG” performance.
For Quality, we use the RAG numbers reported by EntiGraph.